

آشنایی با SVM یا ماشین بردار پشتیبان:
یکی از الگوریتم ها و روشهای بسیار رایج در حوزه دسته بندی داده ها، الگوریتم SVM یا ماشین بردار پشتیبان است که در این مقاله سعی شده است به زبان ساده و به دور از پیچیدگیهای فنی توضیح داده شود.
آشنایی با مفهوم دسته بندی
فرض کنید مجموعه داده ای داریم که ۵۰٪ افراد آن مرد و ۵۰٪ افراد آن زن هستند. این مجموعه داده می تواند مشتریان یک فروشگاه آنلاین باشد. با داشتن یک زیرمجموعه از این داده ها که جنسیت افراد در آن مشخص شده است، می خواهیم قوانینی ایجاد کنیم که به کمک آنها جنسیت بقیه افراد مجموعه را بتوانیم با دقت بالایی تعیین کنیم. تشخیص جنسیت بازدیدکنندگان فروشگاه، باعث می شود بتوانیم تبلیغات جداگانه ای را برای زنان و مردان نمایش دهیم و سودآوری فروشگاه را بالا ببریم . این فرآیند را در علم تحلیل داده، دسته بندی می نامیم .
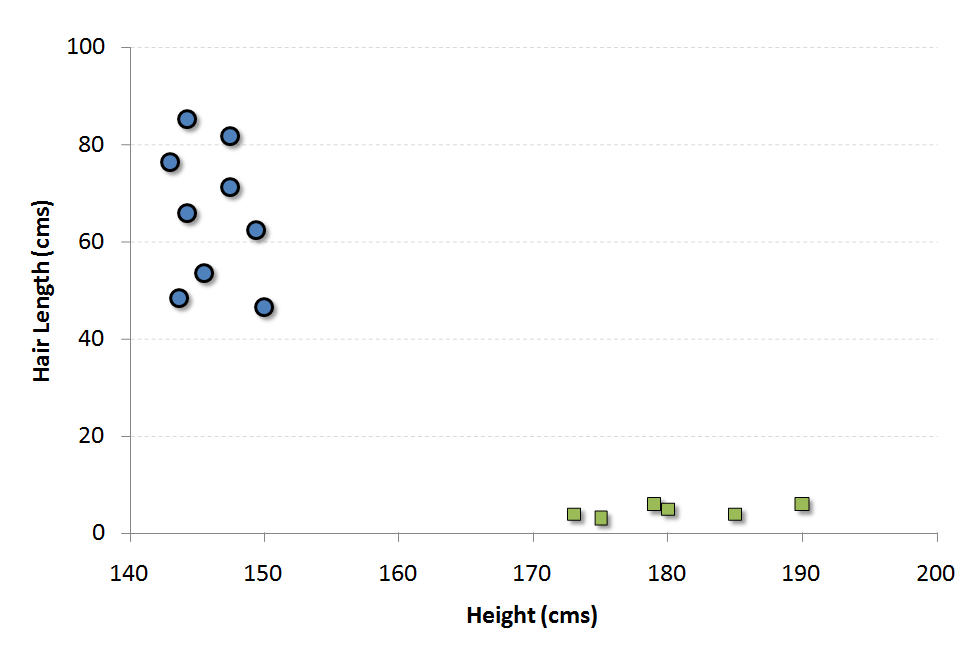
برای توضیح کامل مسأله، فرض کنید دو پارامتری که قرار است جنسیت را از روی آنها تعیین کنیم، قد و طول موی افراد است . نمودار پراکنش قد و طول افراد در زیر نمایش داده شده است که در آن جنسیت افراد با دو نماد مربع (مرد) و دایره (زن) به طور جداگانه نمایش داده شده است .
 با نگاه به نمودار فوق، حقایق زیر به سادگی قابل مشاهده است :
با نگاه به نمودار فوق، حقایق زیر به سادگی قابل مشاهده است :
- مردان در این مجموعه، میانگین قد بلندتری دارند.
- زنان از میانگین طول موی بیشتری برخوردار هستند.
اگر یک داده جدید با قد ۱۸۰cm و طول موی ۴cm به ما داده شود، بهترین حدس ما برای ماشینی این شخص، دسته مردان خواهد بود .
بردارهای پشتیبان و ماشین بردار پشتیبان
بردارهای پشتیبان به زبان ساده، مجموعه ای از نقاط در فضای n بعدی داده ها هستند که مرز دسته ها را مشخص می کنند و مرزبندی و دسته بندی داده ها براساس آنها انجام می شود و با جابجایی یکی از آنها، خروجی دسته بندی ممکن است تغییر کند . به عنوان مثال در شکل فوق ، بردار (۴۵,۱۵۰) عضوی از بردار پشتیبان و متعلق به یک زن است . در فضای دوبعدی ،بردارهای پشتیبان، یک خط، در فضای سه بعدی یک صفحه و در فضای n بعدی یک ابر صفحه را شکل خواهند داد.
در SVM فقط داده های قرار گرفته در بردارهای پشتیبان مبنای یادگیری ماشین و ساخت مدل قرار می گیرند و این الگوریتم به سایر نقاط داده حساس نیست و هدف آن هم یافتن بهترین مرز در بین داده هاست به گونه ای که بیشترین فاصله ممکن را از تمام دسته ها (بردارهای پشتیبان آنها) داشته باشد .
چگونه یک ماشین بر مبنای بردارهای پشتیبان ایجاد کنیم ؟
به ازای داده های موجود در مثال فوق، تعداد زیادی مرزبندی می توانیم داشته باشیم که سه تا از این مرزبندی ها در زیر نمایش داده شده است.
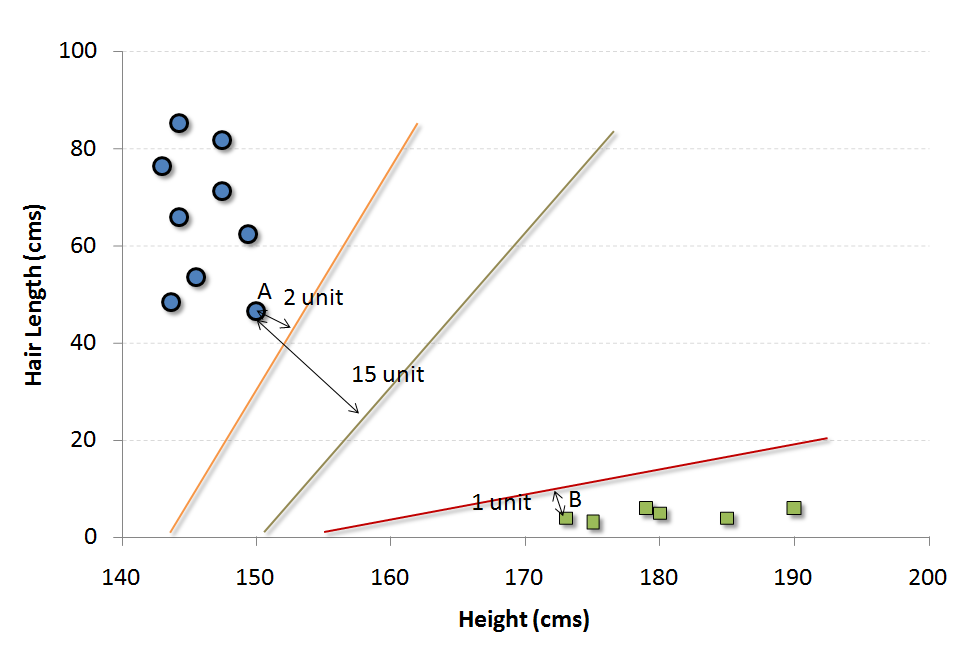 سوال اینجاست که بهترین مرزبندی در این مسأله کدام خط است ؟
سوال اینجاست که بهترین مرزبندی در این مسأله کدام خط است ؟
یک راه ساده برای انجام اینکار و ساخت یک دسته بند بهینه ، محاسبه فاصله ی مرزهای به دست آمده با بردارهای پشتیبان هر دسته (مرزی ترین نقاط هر دسته یا کلاس) و در نهایت انتخاب مرزیست که از دسته های موجود، مجموعاً بیشترین فاصله را داشته باشد که در شکل فوق خط میانی ، تقریب خوبی از این مرز است که از هر دو دسته فاصله ی زیادی دارد. این عمل تعیین مرز و انتخاب خط بهینه (در حالت کلی ، ابر صفحه مرزی) به راحتی با انجام محاسبات ریاضی نه چندان پیچیده قابل پیاده سازی است .
توزیع غیر خطی داده ها و کاربرد ماشین بردار پشتیبان
اگر داده ها به صورت خطی قابل تفکیک باشند، الگوریتم فوق می تواند بهترین ماشین را برای تفکیک داده ها و تعیین دسته یک رکورد داده، ایجاد کند اما اگر داده ها به صورت خطی توزیع شده باشند (مانند شکل زیر )، SVM را چگونه تعیین کنیم ؟
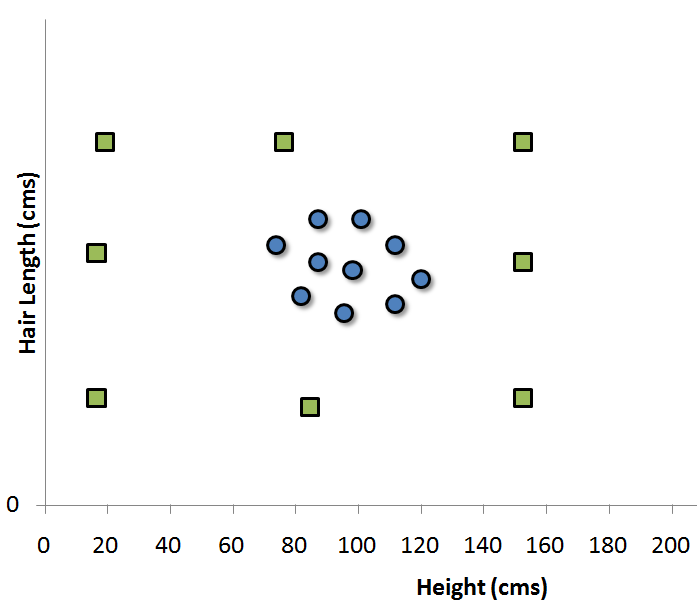
در این حالت، ما نیاز داریم داده ها را به کمک یک تابع ریاضی (Kernel functions) به یک فضای دیگر ببریم (نگاشت کنیم ) که در آن فضا، داده ها تفکیک پذیر باشند و بتوان SVM آنها را به راحتی تعیین کرد. تعیین درست این تابع نگاشت در عملکرد ماشین بردار پشتیبان موثر است که در ادامه به صورت مختصر به آن اشاره شده است.
با فرض یافتن تابع تبدیل برای مثال فوق، فضای داده ما به این حالت تبدیل خواهد شد :
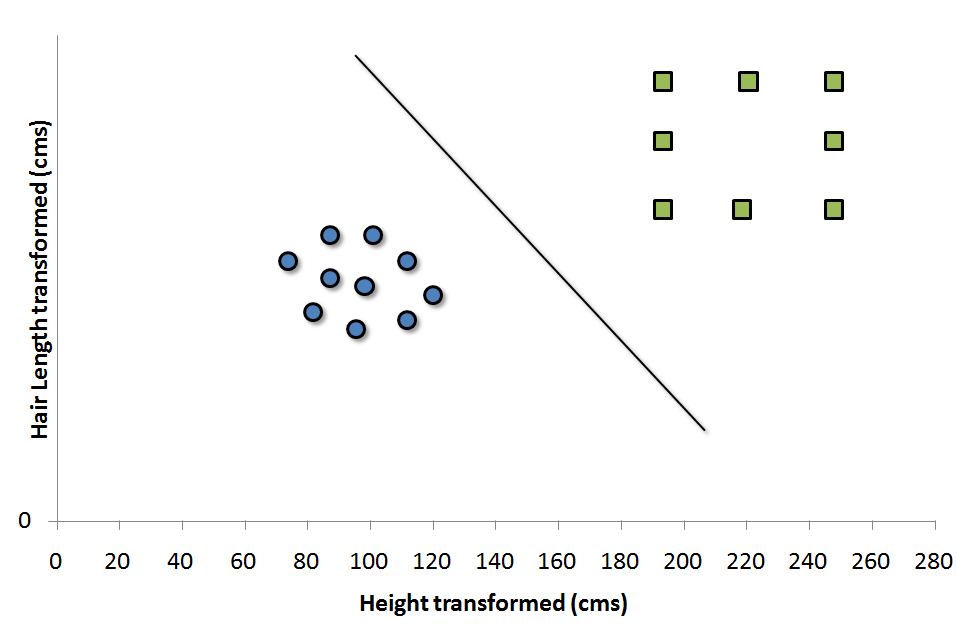
در این فضای تبدیل شده، یافتن یک SVM به راحتی امکان پذیر است .
نگاهی دقیق تر به فرآیند ساخت SVM
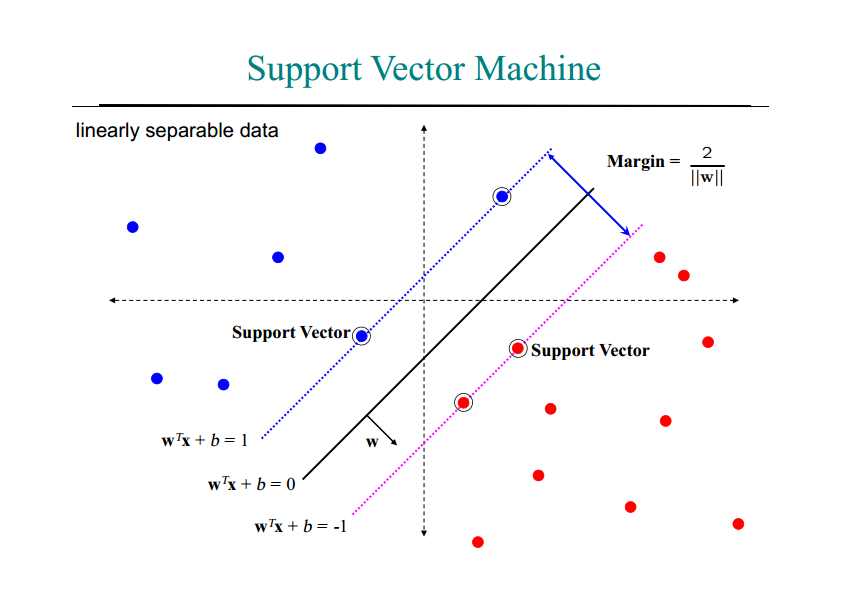
همانطور که اشاره شد،ماشین بردار پشتیبان یا SVM داده ها را با توجه به دسته های از پیش تعیین شده آنها به یک فضای جدید می برد به گونه ای که داده ها به صورت خطی (یا ابر صفحه ) قابل تفکیک و دسته بندی باشند و سپس با یافتن خطوط پشتیبان (صفحات پشتیبان در فضای چند بعدی) ، سعی در یافتن معادله خطی دارد که بیشترین فاصله را بین دو دسته ایجاد می کند.
در شکل زیر داده ها در دو دوسته آبی و قرمز نمایش داده شده اند و خطوط نقطه چین ، بردار های پشتیبان متناظر با هر دسته را نمایش می دهند که با دایره های دوخط مشخص شده اند و خط سیاه ممتد نیز همان SVM است . بردار های پشتیبان هم هر کدام یک فرمول مشخصه دارند که خط مرزی هر دسته را توصیف می کند.
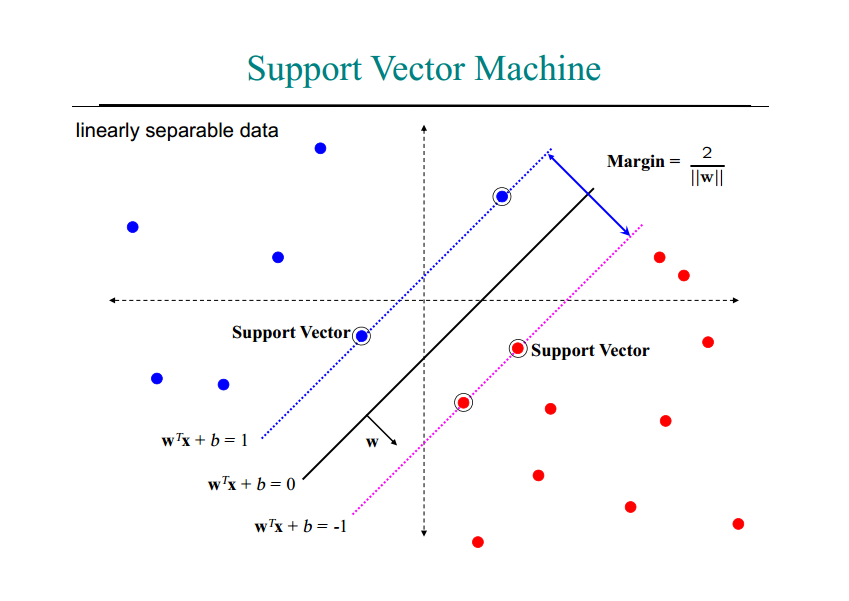
برای استفاده از SVM در مورد داده های واقعی ، چندین نکته را باید رعایت کنید تا نتایج قابل قبولی را بگیرید
- ابتدا داده ها را پالایش کنید (نقاط پرت ، داده های ناموجود و …..)
- داده را عددی و نرمال کنید . این مباحث را در مقالات پیش پردازش داده ها دنبال کنید. به طور خلاصه ، داده هایی مانند جنسیت، رشته تحصیلی و … را به عدد تبدیل کنید و سعی کنید مقادیر همه صفات بین یک تا منهای یک [۱,-۱] نرمال شوند تا بزرگ یا کوچک بودن مقادیر یک ویژگی داده ها، ماشین را تحت تاثیر قرار ندهد .
- کرنل های مختلف را امتحان و به ازای هر کدام، با توجه به مجموعه داده آموزشی که در اختیار دارید و دسته بندی داده های آنها مشخص است، دقت SVM را اندازه گیری کنید و در صورت نیاز پارامتر های توابع تبدیل را تغییر دهید تا جواب های بهتری بگیرید. این کار را برای کرنل های مختلف هم امتحان کنید . می توانید از کرنل RBF شروع کنید .
نقاط ضعف ماشین بردار پشتیان
- این نوع الگوریتم ها، محدودیت های ذاتی دارند مثلا هنوز مشخص نشده است که به ازای یک تابع نگاشت ، پارامترها را چگونه باید تعیین کرد.
- ماشینهای مبتنی بر بردار پشتیبان به محاسبات پیچیده و زمان بر نیاز دارند و به دلیل پیچیدگی محاسباتی، حافظه زیادی نیز مصرف می کنند.
- داده های گسسته و غیر عددی هم با این روش سازگار نیستند و باید تبدیل شوند.
با این وجود، SVM ها دارای یک شالوده نظری منسجم بوده و جواب های تولید شده توسط آنها ، سراسری و یکتا می باشد. امروزه ماشینهای بردار پشتیبان، به متداول ترین تکنیک های پیش بینی در داده کاوی تبدیل شده اند.
سخن پایانی
ماشینهای بردار پشتیبان، الگوریتم های بسیار قدرتمندی در دسته بندی و تفکیک داده ها هستند بخصوص زمانی که با سایر روشهای یادگیری ماشین مانند روش جنگل تصادفی تلفیق شوند. این روش برای جاهایی که با دقت بسیار بالا نیاز به ماشینی داده ها داریم، به شرط اینکه توابع نگاشت را به درستی انتخاب کنیم، بسیار خوب عمل می کند .
ساختار اصلی این نوشتار از روی یک مقاله سایت آنالیتیکزویدیا برداشته شده است و برای دو بخش پایانی مقاله هم از کتاب «داده کاوی پیشرفته : مفاهیم و الگوریتم ها» دکتر شهرابی استفاده شده است .
منبع : بیگ دیتا

بهترین وبسایتی که تاحالا دیدم.ازتون متشکرم