

خوشه بندی K-Means
روش خوشه بندی K-Means علیرغم سادگی آن یک روش پایه برای بسیاری از روشهای خوشهبندی دیگر محسوب میشود. این روش روشی انحصاری و مسطح محسوب میشود. برای این الگوریتم شکلهای مختلفی بیان شده است. ولی همه آنها دارای روالی تکراری هستند که برای تعدادی ثابت از خوشهها سعی در تخمین موارد زیر دارند:
- بدست آوردن نقاطی به عنوان مراکز خوشهها این نقاط در واقع همان میانگین نقاط متعلق به هر خوشه هستند.
- نسبت دادن هر نمونه داده به یک خوشه که آن داده کمترین فاصله تا مرکز آن خوشه را دارا باشد.
در نوع سادهای از این روش ابتدا به تعداد خوشههای مورد نیاز نقاطی به صورت تصادفی انتخاب میشود. سپس در دادهها با توجه با میزان نزدیکی (شباهت) به یکی از این خوشهها نسبت داده میشوند و بدین ترتیب خوشههای جدیدی حاصل میشود. با تکرار همین روال میتوان در هر تکرار با میانگینگیری از دادهها مراکز جدیدی برای انها محاسبه کرد و مجدادأ دادهها را به خوشههای جدید نسبت داد. این روند تا زمانی ادامه پیدا میکند که دیگر تغییری در دادهها حاصل نشود. تابع زیر به عنوان تابع هدف مطرح است.
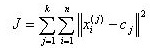
که || || معیار فاصله بین نقطه i ام با مرکز خوشه jام است.
فلوچارت الگوریتم خوشهبندی K-Means بصورت زیر می باشد:
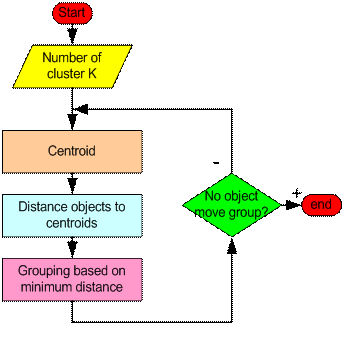
الگوريتم زير الگوريتم پايه براي اين روش محسوب ميشود:
- در ابتداK نقطه به عنوان به نقاط مراکز خوشهها انتخاب ميشوند.
- هر نمونه داده به خوشهاي که مرکز آن خوشه کمترين فاصله تا آن داده را داراست، نسبت داده ميشود.
- پس تعلق تمام دادهها به يکي از خوشهها براي هر خوشه يک نقطه جديد به عنوان مرکز محاسبه ميشود. (ميانگين نقاط متعلق به هر خوشه)
- مراحل2 و 3 تکرار ميشوند تا زماني که ديگر هيچ تغييري در مراکز خوشهها حاصل نشود.
برای دریافت کد متلب الگوریتم Kmeans به همراه توضیحات خط به خط کد بر روی لینک زیر کلیک فرمایید
برای دریافت کد الگوریتم Kmeans به زبان c# به همراه توضیحات بر روی لینک زیر کلیک فرمایید:
پیاده سازی الگوریتم K means در سی شارپ
برای دریافت اسلاید فارسی و کامل از الگوریتم خوشه بندی k-means بر روی لینک زیر کلیک کنید
برای آشنایی با روال کار و فلوچارت الگوریتم K-means بر روی لینک زیر کلیک کنید.
برای دریافت کد متلب خوشه بندی دیتای Iris با الگوریتم Kmeans بر روی لینک زیر کلیک فرمایید:
